I'm a PhD at the Tübingen AI Center, advised by Matthias Bethge and Maksym Andriushchenko. I work on understanding LLM capabilities and failure modes, with a focus on long-horizon evaluation and safety.
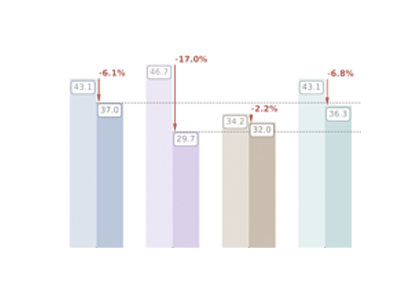
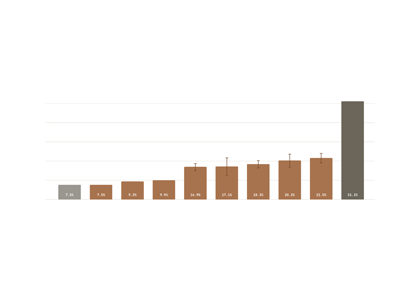
My research asks: how do we rigorously measure what LLMs can and can't do—especially in extended autonomous settings. I am working on PostTrainBench, a benchmark measuring whether CLI agents can autonomously post-train LLMs, and led the Sober Look at Reasoning project showing that many claimed reasoning improvements are within noise margins. At ARENA 6.0, I built a long-horizon agent benchmark.
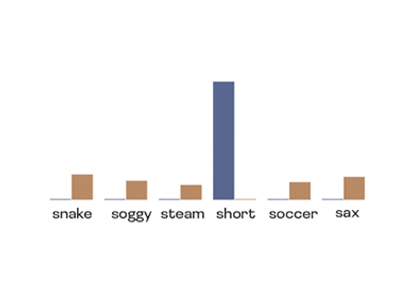
I also worked on mechanistic interpretability. At LASR Labs with Joseph Bloom (UK AISI), we discovered "feature absorption" -- a systematic failure mode in Sparse Autoencoders. At Microsoft Research with Navin Goyal, I studied how harmful concepts transform during post-training.
Previously, I worked in computational neuroscience at the Max Planck Institute for Biological Cybernetics and EPFL, modeling how visual features map onto neural activity. I hold a dual degree in Computer Science and Biological Sciences from BITS Pilani.