Hardik Bhatnagar

I’m a PhD student at the Tübingen AI Center, advised by Prof. Matthias Bethge, working on AI security with a focus on evaluating LLMs and understanding their capabilities and failure modes.
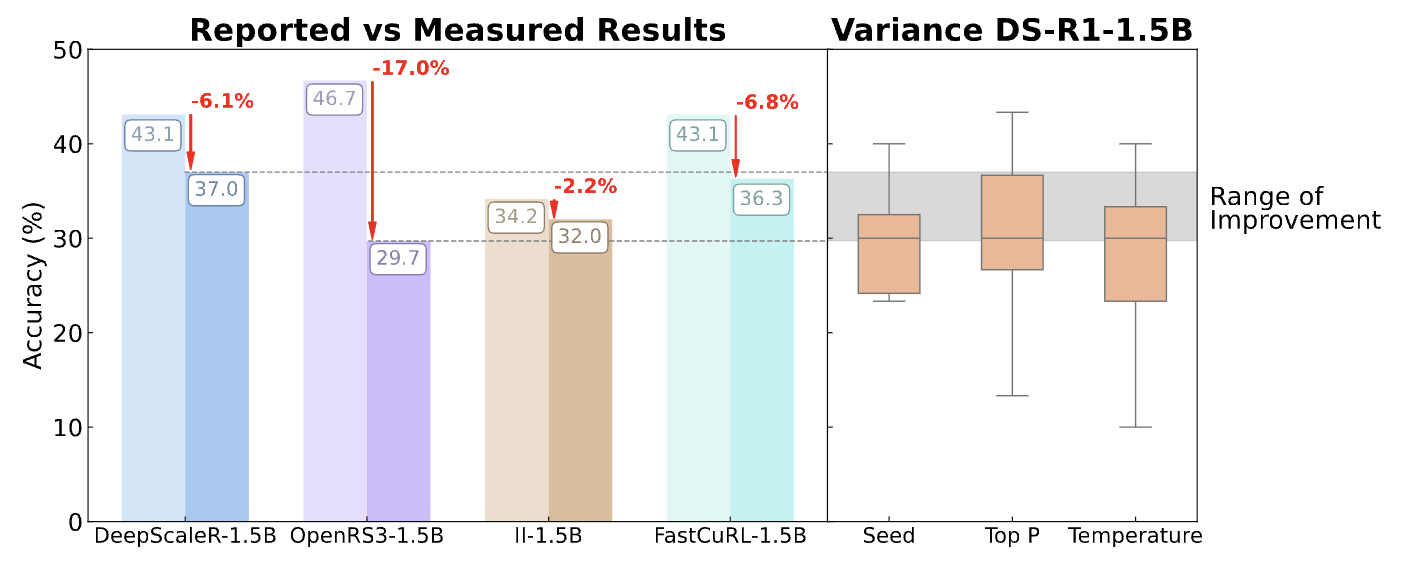
My recent research centers on empirical evaluations of long-horizon capabilities and alignment-relevant behaviors in LLMs. I recently took part in the ARENA program, where I built an unsaturated long-horizon benchmark for LLM agents. Previously, I worked on mechanistic interpretability, investigating how LLMs represent information internally.
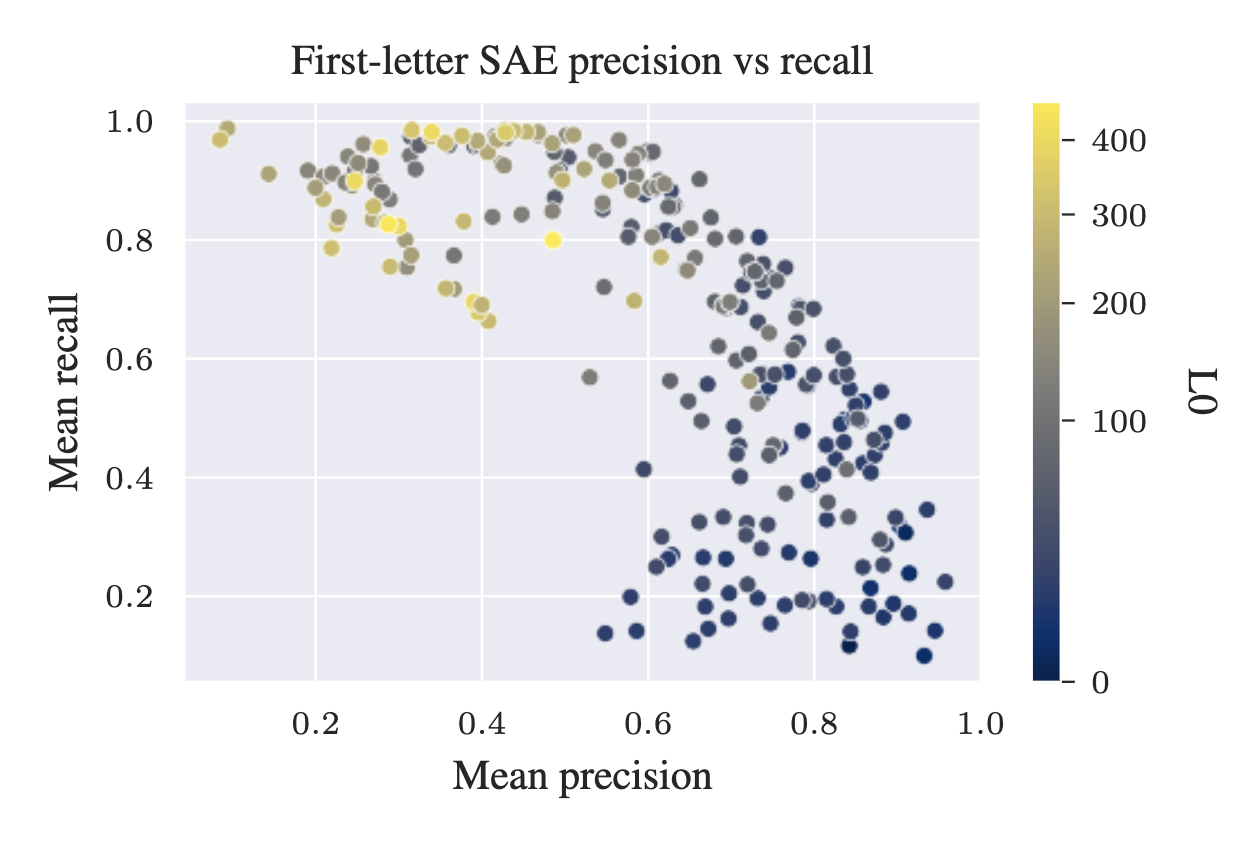
At Microsoft Research with Navin Goyal, I studied how harmful concepts are transformed during post-training stages of LLMs. At LASR Labs with Joseph Bloom (UK AISI), we investigated whether Sparse Autoencoders (SAEs) extract interpretable features from LLMs, leading to the discovery of a novel failure mode we termed “feature absorption.”
In a previous life, I worked in computational neuroscience at the Max Planck Institute for Biological Cybernetics with Prof. Andreas Bartels and at EPFL, modeling how image features map onto neural activity in the brain.
I hold a dual degree in Computer Science and Biological Sciences from BITS Pilani, India.